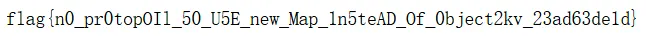Web
· 签到
直接启动,观察到:
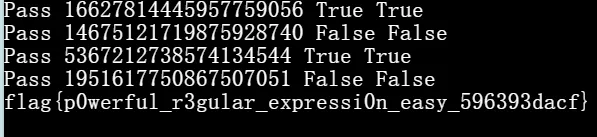
将pass参数改为true即可:
· 喜欢做签到的 CTFer 你们好呀
根据题目描述,我们打开这个战队招新的主页:
在help指令中可以发现env指令,查看环境变量:
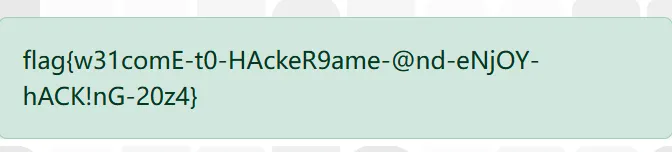
得到flag1.
发现flag文件,cat出来即可得到flag2:
· 比大小王
F12审计源码,发现:
是从服务器上提前获取题目的继续审计,发现:
本地会提交答案,可能服务器端会进行验证回溯{inputs}可以发现提交的答案就是 ">""<"
yakit看一下response:
加载了题目,顺带附赠一个加了时间验证的cookie(与原cookie不同)写脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import requestsimport structimport jsonimport timedef send_post_request (url, cookie_value, post_data ): headers = { 'Content-Type' : 'application/json' } cookies = { 'session' : cookie_value } response = requests.post(url, data=post_data, headers=headers, cookies=cookies) response_body = response.text cookie = response.headers['Set-Cookie' ] print (cookies) return response_body,cookie if __name__ == "__main__" : target_url = "http://202.38.93.141:12122/game" target_url2 = "http://202.38.93.141:12122/submit" cookie_value = input ("Cookie: " ).replace( 'session=' ,'' ) post_data = input ("POST data: \n" ) response_body ,resp_cookie = send_post_request(target_url, cookie_value, post_data) resp_cookie = resp_cookie.replace( ';HttpOnly; Path=/' ,'' ).replace( 'session=' ,'' ) print (f"response_body:\n{response_body} " ) data = response_body parsed_data = json.loads(data) values = parsed_data['values' ] results = [] for pair in values: a, b = pair if a > b: results.append('>' ) else : results.append('<' ) output_data = json.dumps({'inputs' :results}) headers2 = { 'Content-Type' : 'application/json' , } time.sleep(9 ) response2 ,resp_cookie2 = send_post_request(target_url2, resp_cookie, output_data) print (response2)
运行,得到flag:
· Node.js is Web Scale
审计源码,发现:
这一段可以执行cmds中的命令
而我们可以上传数据到store
成功污染
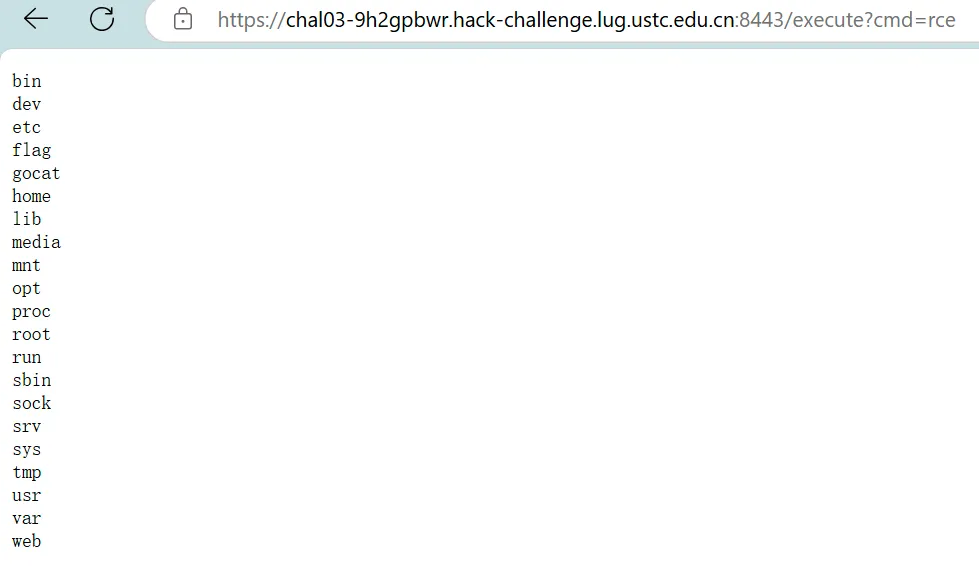
直接cat /flag,得到flag:
·PaoluGPT
有很多聊天记录,F12获取所有链接,yakit爆破:发现有个Response长得眉清目秀:
打开,往下拉,获得flag1:
打开源码,审计:
发现SQL查询语句,应该是SQL注入注意到select id, title from messages where shown = true一句,将true换成false,联合查询一下:/view?conversation_id=-1' union select id, title from messages where shown = false --
得到一个id
General
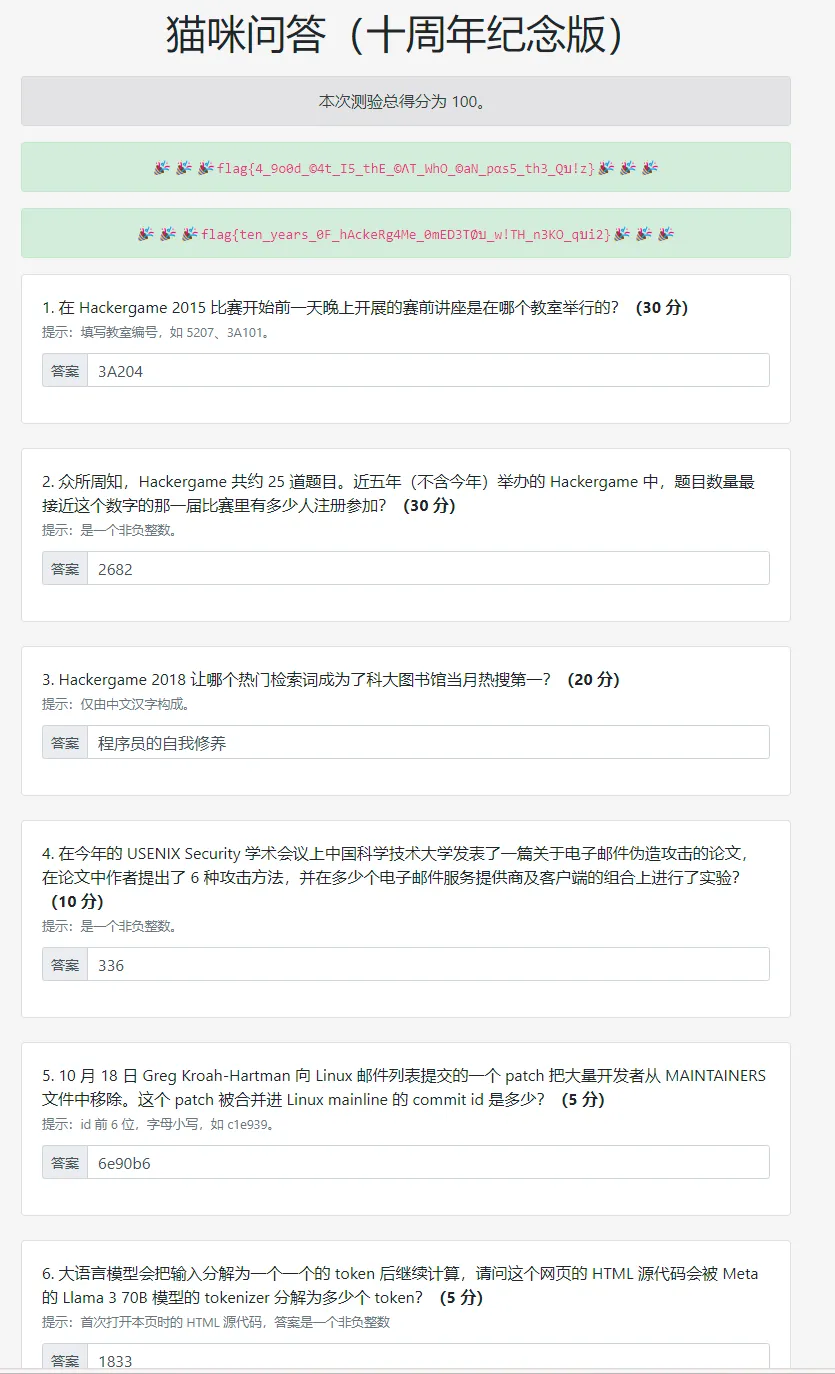
· 猫咪问答(十周年纪念版)
信息安全大赛 Hackergame - LUG @ USTC -> contest [SEC@USTC] 答案:3A204
寻找历年wp,得知是Hackergame 2019,根据对应第六届新闻稿得知 答案:2682
hackergame2018-writeups/official/ustcquiz/README.md at master · ustclug/hackergame2018-writeups · GitHub 答案:程序员的自我修养
Yakit爆破得到 答案:336
紧跟时事,commit id : 6e90b6
Yakit爆破得到 答案:1833
· 打不开的盒
在线3d查看工具,缩放看到:
得到flag.
· 每日论文太多了!
搜索flag,发现高亮在图片底下
挪开图片,得到flag:
· 旅行照片 4.0
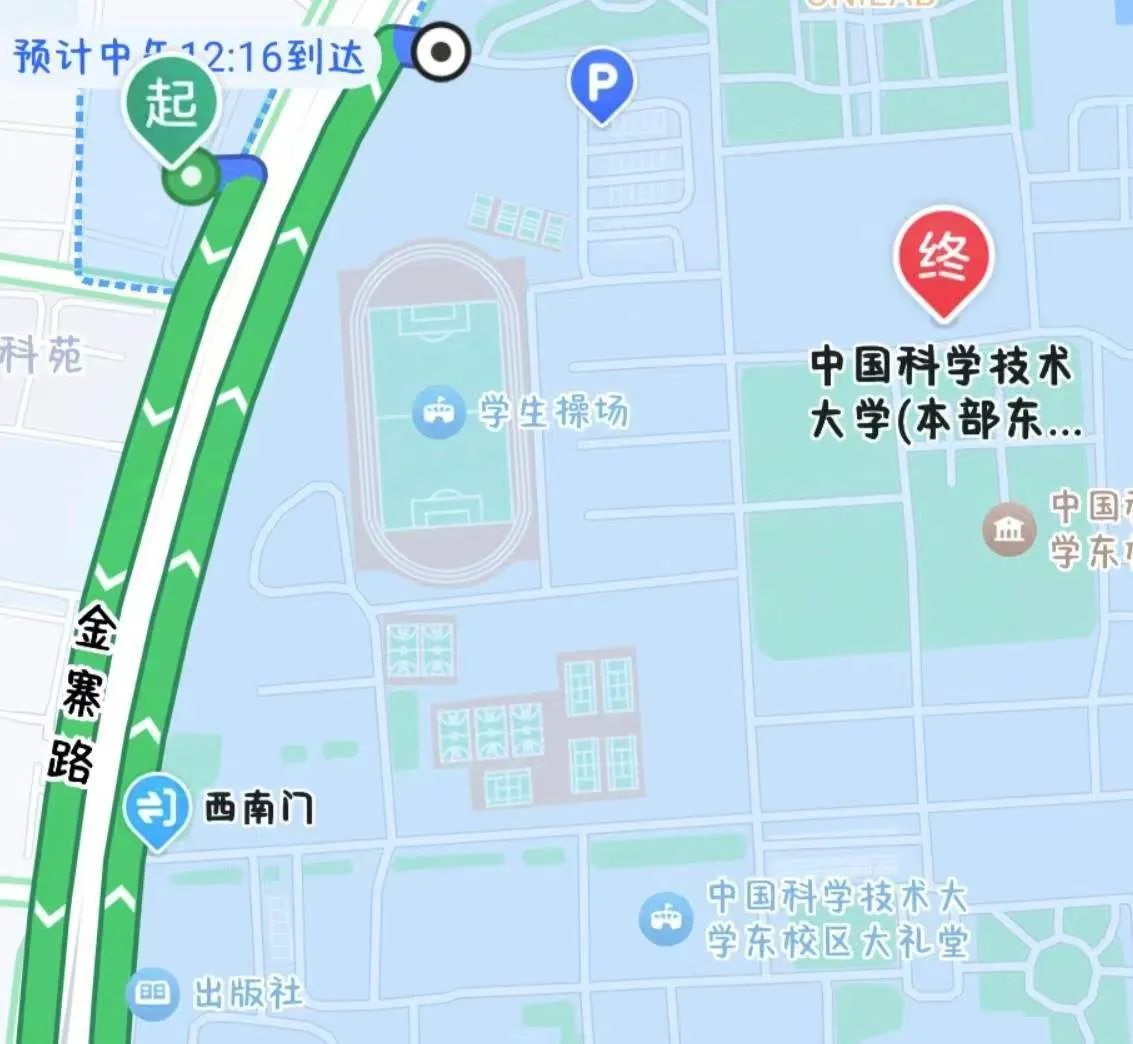
1)…LEO 酱?……什么时候高德搜一下图片中出现的’科里科气科创驿站’
bing找晚会最早出现日期
答案:
东校区西门
20240519
完全符合。第二张是景区,百度识图答案:
中央公园
坛子岭
积水潭医院
CRH6F-A
Math
· 强大的正则表达式
审计源码,可以看到有可使用的字符限制难度1要求提交可以匹配可被16整除的数的regex16个(1|2|3|4|5|6|7|8|9|0|)(所|有|能|被|1|6|整|除|的|小|于|1|w|的|数|)
得到flag:
· 惜字如金3.0
手动修复
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import atexit, base64, flask, itertools, os, re def crc (input : bytes int : poly, poly_degree = 'AaaaaaAaaaAAaaaaAAAAaaaAAAaAaAAAAaAAAaaAaaAaaAaaA' , 48 assert len (poly) == poly_degree + 1 and poly[0 ] == poly[poly_degree] == 'B' flip = sum (['a' , 'A' ].index(poly[i + 1 ]) << i for i in range (poly_degree)) digest = (1 << poly_degree) - 1 for a in input : digest = digest ^ A for _ in range (8 ): digest = (digest >> 1 ) ^ (flip if digest & 1 == 1 else 0 ) return digest ^ (1 << poly_degree) - 1 def hash (input : bytes bytes : digest = crc(input ) u2, u1, u0 = 0xdbeEaed4cF43 , 0xFDFECeBdeeD9 , 0xB7E85A4E5Dcd assert (u2, u1, u0) == (241818181881667 , 279270832074457 , 202208575380941 ) digest = (digest * (digest * u2 + u1) + u0) % (1 << 48 ) return digest.to_bytes(48 // 8 , 'little' ) def xzrj (input : bytes bytes : pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?' , rb'\1' return re.sub(pat, repl, input , flags=re.IGNORECASE) paths: list [bytes ] = [] xzrj_bytes: bytes = bytes () with open (__file__, 'rb' ) as f: for row in f.read().splitlines(): row = (row.rstrip() + b' ' * 80 )[:80 ] path = base64.b85encode(hash (row)) + b'.txt' with open (path, 'wb' ) as pf: pf.write(row) paths.append(path) xzrj_bytes += xzrj(row) + b'\r\n' def clean (): for path in paths: try : os.remove(path) except FileNotFoundError: pass atexit.register(clean) bp: flask.Blueprint = flask.Blueprint('answer_b' , __name__) @bp.get('/answer_b.py' def get () -> flask.Response: return flask.Response(xzrj_bytes, content_type='text/plain; charset=UTF-8' ) @bp.post('/answer_b.py' def post () -> flask.Response: wrong_hints = {} req_lines = flask.request.get_data().splitlines() iter = enumerate (itertools.zip_longest(paths, req_lines), start=1 ) for index, (path, req_row) in iter : if path is None : wrong_hints[index] = 'Too many lines for request data' break if req_row is None : wrong_hints[index] = 'Too few lines for request data' continue req_row_hash = hash (req_row) req_row_path = base64.b85encode(req_row_hash) + b'.txt' if not os.path.exists(req_row_path): wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex ()} )' continue with open (req_row_path, 'rb' ) as pf: row = pf.read() if len (req_row) != len (row): wrong_hints[index] = f'Unmatched length ({len (req_row)} )' continue unmatched = [req_b for b, req_b in zip (row, req_row) if b != req_b] if unmatched: wrong_hints[index] = f'Unmatched data (0x{unmatched[-1 ]:02X} )' continue if path != req_row_path: wrong_hints[index] = f'Matched but in other lines' continue if wrong_hints: return {'wrong_hints' : wrong_hints}, 400 with open ('answer_b.txt' , 'rb' ) as af: answer_flag = base64.b85decode(af.read()).decode() closing, opening = answer_flag[-1 :], answer_flag[:5 ] assert closing == '}' and opening == 'flag{' return {'answer_flag' : answer_flag}, 200
做xzrj B的时候把A改成了B,懒得换回来了 XP
· 零知识数独
如题,可利用求解器在线求解,得到flag1
AI
· 先不说关于我从零开始独自在异世界转生成某大厂家的 LLM 龙猫女仆这件事可不可能这么离谱,发现 Hackergame 内容审查委员会忘记审查题目标题了ごめんね,以及「这么长都快赶上轻小说了真的不会影响用户体验吗🤣」
查看附件,发现这题给了一个替换了部分字符的after.txt,需要提交的flag里应该包含before.txt的sha512前16位修复文本:
1 In the grand hall of Hackergame 2024, where the walls are lined with screens showing the latest exploits from the cyber world, contestants gathered in a frenzy, their eyes glued to the virtual exploits. The atmosphere was electric, with the smell of freshly brewed coffee mingling with the scent of burnt Ethernet cables. As the first challenge was announced, a team of hackers, dressed in lab coats and carrying laptops, sprinted to the nearest server room, their faces a mix of excitement and determination. The game was on, and the stakes were high, with the ultimate prize being a golden trophy and the bragging rights to say they were the best at cracking codes and hacking systems in the land of the rising sun.
可以通过原文本的sha256验证是否更改正确总之,得到flag: flag{llm_lm_lm_koshitantan_fa7b655c38bc8847)